
The question I think VPP Ops leaders should be asking now
The next advantage in VPP operations probably won’t come from sending more signals. It will come from knowing which response pathways you can actually trust.
I keep coming back to the same thought in VPP operations.
As fleets grow, the harder question is no longer just how much DER capacity is enrolled.
It is whether the team can clearly explain how value turned into fleet response — or leaked away — across real programs.
That feels especially relevant now because battery-led programs are growing, more flexibility is being asked of distributed assets, and the operating burden after a miss is becoming harder to ignore.
The point I’d make is simple:
The next advantage in VPP operations probably won’t come from sending more signals. It will come from knowing which response pathways you can actually trust.
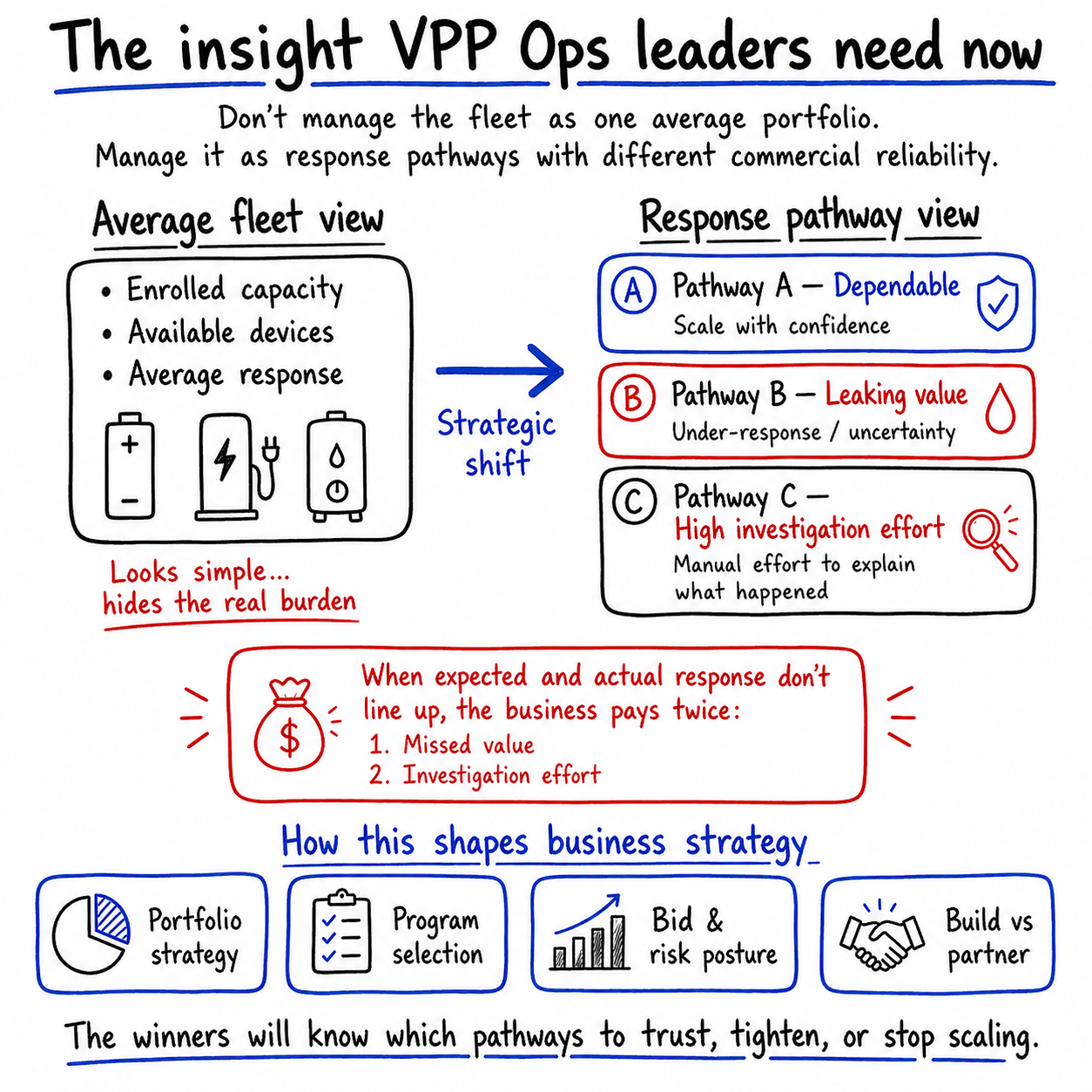
A lot of teams still look at the fleet too high up.
They see:
- enrolled capacity
- available devices
- average response
- overall program performance
But that is not where the real burden sits.
A signal goes out.
A cohort is expected to respond.
Part of it does not.
Now the team is left working backwards across control pathways, telemetry, OEM behaviour, and exceptions just to understand what happened.
That is where the business pays twice.
First in the miss itself.
Then in the effort required to explain it.
That is why I think VPP Ops leaders need a different lens.
Not:
“How big is the fleet?”
But:
“Which response pathways are actually dependable, which are leaking value, and which are creating repeat effort for the team?”
That question matters because it shapes real business decisions.
It affects:
- which cohorts you trust in high-value intervals
- which programs are worth leaning into
- where to be more conservative commercially
- where to tighten integrations or push vendors harder
- where not to keep scaling a weak pathway
In other words, the fleet should not be managed as one average portfolio.
It should be managed as a set of response pathways with different commercial reliability.
Some pathways are dependable enough to scale with confidence.
Some are quietly leaking value.
Some create more investigation effort than they are worth.
That is the strategic shift.
For operators in Australia and New Zealand, this matters because distributed flexibility is becoming more important, but explainable response is still uneven. Enrollment alone is not enough. Dependable, explainable response is what turns flexibility into a scalable business asset.
If I were looking at this inside a VPP today, I’d start smaller than the whole fleet.
I’d pick one costly workflow first — ideally one that is:
- commercially important
- recurring
- hard to explain when it falls short
- painful enough that the team already feels the burden
For many teams, that will be a battery-led response workflow.
Then I’d ask five questions:
- What was sent?
- Who was expected to respond?
- What actually happened?
- Where did the chain break down?
- What needs attention before the next interval?
That alone usually tells you whether the real issue is:
- signal clarity
- targeting
- pathway reliability
- telemetry visibility
- exception handling
- repeated uncertainty around the same cohort
That is also where I think ConstraintOps fits.
Not as a big platform story.
Just as a way to help a team get a clearer handle on one live signal-to-response workflow first — clear enough to see what happened, where value was lost, where the breakdown occurred, and what needs attention next.
The point is not more dashboards.
The point is giving Ops leaders evidence they can actually use to decide:
- where to trust
- where to tighten
- where to be more conservative
- and where the business is quietly leaking value
That feels like the more important operating question now.
Not “how much have we enrolled?”
But:
Which pathways are dependable enough to scale, and which are costing us more than we realise?
— Pradeep (Helping you make that hidden middle layer visible and explainable)
P.S. You've received this email because we're connected on LinkedIn. Feel free to unsubscribe if the insights are unrelated.