
Why VPP Readiness Starts Again After the Signal
A VPP can be ready enough to send a signal, but not ready enough to prove the response. That distinction matters as operators add new value streams and rely on more fragmented DER fleets.
Readiness Is Not Response Proof.
A VPP can be ready enough to send a signal, but not ready enough to prove the response.
That distinction is becoming more important as operators try to add new value streams, participate in more programs, and make better use of existing DER fleets.
Most readiness discussions start with execution.
Can we receive the signal?
Can we process the inputs?
Can we decide what should happen?
Can we select the right cohort?
Can we send the instruction?
Those are real readiness questions. Without them, nothing operational happens.
But they are not the whole question.
The harder question starts after the signal.
Did the fleet actually respond?
Did the response arrive in the right window?
Was the delivered shape close enough to what was expected?
Which pathway behaved differently?
Which assets were unavailable?
Which telemetry can be trusted?
Where did the value leak?
That is where readiness becomes commercial.
Because when a new value stream is being assessed, the question is not only whether a VPP can technically participate. It is whether the operator can trust the response enough to lean on it again.
There are two layers of readiness.
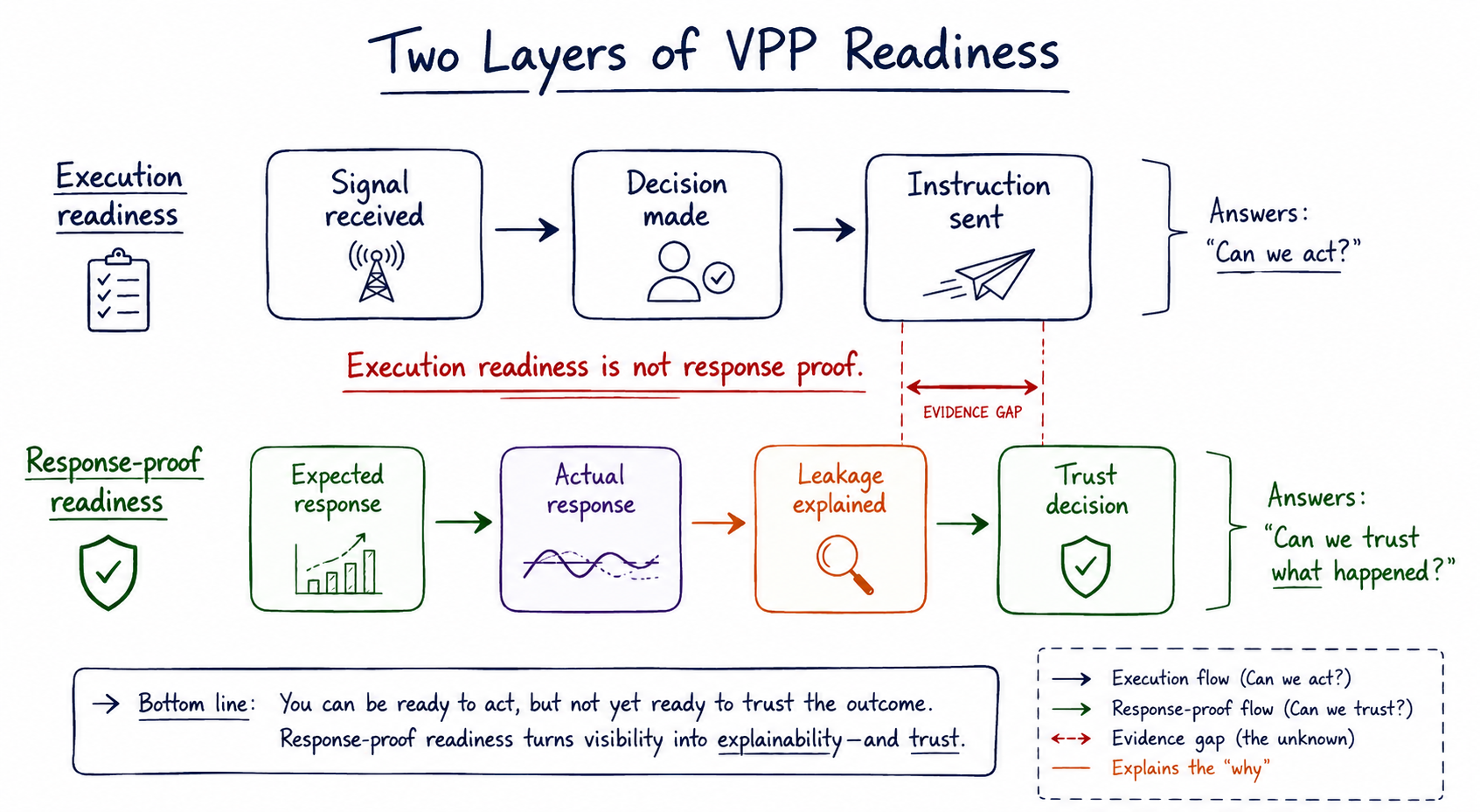
The first is execution readiness:
Signal received → decision made → instruction sent
The second is response-proof readiness:
Expected response → actual response → leakage explained → trust decision
Most teams are under pressure to strengthen the first layer. That makes sense. Market opportunities are moving. Program deadlines are compressed. Internal resources are limited. Teams need the base capability to act.
But as soon as the fleet is dispatched, the second layer starts to matter.
If response is weaker than expected, someone has to explain it.
Was the cohort wrong?
Was the control pathway delayed?
Was the device unavailable?
Was the metering incomplete?
Was the instruction executed but not visible?
Was the expected baseline wrong?
Without that evidence, every follow-up decision becomes harder.
Should this provider be derated?
Should this OEM pathway be improved?
Should this cohort be excluded next time?
Should engineering build a bespoke integration?
Should operations keep treating this as a manual exception?
Should leadership trust the next revenue forecast from this fleet segment?
This is why expected-versus-actual is not just a reporting view.
It is an operating discipline.
The event itself may create one form of value leakage. But the investigation that follows creates another. Time gets spent reconciling signals, telemetry, eligibility, control instructions, and pathway behaviour.
The more fragmented the fleet, the more expensive that investigation becomes.
And when the evidence is weak, teams tend to become conservative.
They derate.
They fall back.
They avoid leaning on uncertain capacity.
They delay decisions about what to fix.
That may protect reliability, but it also limits value realisation.
This is especially painful in residential flexibility, where margins are already thin, customer trust is fragile, and the cost-to-serve can rise quickly. If the team cannot prove what part of the fleet is actually bankable, then every new value stream carries more operational uncertainty than the spreadsheet suggests.
The point is not that every VPP needs a bigger platform.
The point is narrower.
Before operators scale a new workflow, they need one live signal-to-response chain that is clear enough to review.
What was sent.
Who was expected to respond.
What actually happened.
Where response leaked.
What the evidence supports.
What needs attention next.
That is the practical difference between readiness as a claim and readiness as an operating baseline.
A fleet is not truly ready just because it can be instructed.
It is ready when the operator can prove what happened next.
Speak to you in my next issue. Take care.
— Pradeep (Helping you make that hidden middle layer profitable)
P.S. You've received this email because we're connected on LinkedIn. Feel free to unsubscribe if the insights are unrelated.